# 28. 找出字符串中第一个匹配项的下标
简单
给你两个字符串
haystack和needle,请你在haystack字符串中找出needle字符串的第一个匹配项的下标(下标从 0 开始)。如果needle不是haystack的一部分,则返回-1。示例 1:
输入:haystack = "sadbutsad", needle = "sad" 输出:0 解释:"sad" 在下标 0 和 6 处匹配。 第一个匹配项的下标是 0 ,所以返回 0 。示例 2:
输入:haystack = "leetcode", needle = "leeto" 输出:-1 解释:"leeto" 没有在 "leetcode" 中出现,所以返回 -1 。提示:
1 <= haystack.length, needle.length <= 104haystack和needle仅由小写英文字符组成
# 什么是KMP
KMP 由 Knuth,Morris、Pratt 三位学者发明,取他们名字的首字母命名,即KMP算法。
# KMP有什么用
假设现在有一个文本字符串 aabaabaaf 和一个模板字符串 aabaaf,现在要求在文本串中找出模板串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。
如果不想用双重 for 循环的暴力解法,就需要用到 KMP 算法思想。
KMP的主要思想是当出现字符串不匹配时,可以知道一部分已经匹配的文本内容,从而避免从头重新做匹配。 所以 KMP 的重点是如何记录已经匹配的文本内容。
# 什么是前缀表
什么是前缀和后缀?
前缀: 必须包含第一个字母但不包含最后一个字母的连续子串
后缀:必须包含最后一个字母但不包含第一个字母的连续子串
aabaaf 的所有前缀:a; aa; aab; aaba; aabaa
aabaaf 的所有后缀:f; af; aaf; baaf; abaaf
后缀也是从左往右读的。
此时就可以引入「最长公共前后缀」(也叫「最长相等前后缀」)的概念了,即一个字符串的前缀集和后缀集中最长的相等的字符串。
前缀表:记录下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。
# 为什么要使用前缀表?
前缀表的任务是当前位置匹配失败,找到上次已经匹配上的位置,再重新匹配。也就是说在某个字符匹配失败时,前缀表会告诉你下一步匹配时模式串应该跳到哪个位置。这就涉及到计算模式串的完整前缀表。next 数组也是一种前缀表。
只用文字描述可能有点抽象,用下面的图来说明:
要在文本串:aabaabaafa 中查找是否出现过一个模式串:aabaaf。
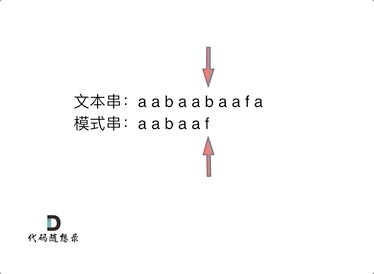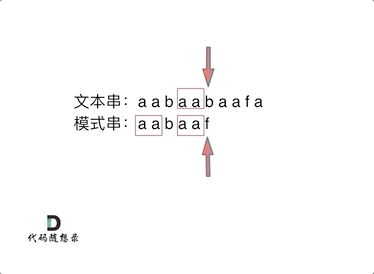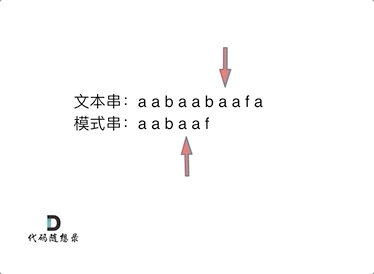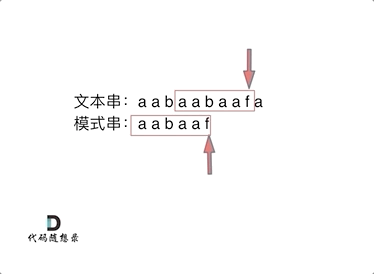
可以看出,当第六个字符b和f不匹配时,如果使用暴力匹配方法,这时需要从头匹配。如果使用前缀表,就不会从头匹配,而是从上次已经匹配的内容aa后开始匹配。
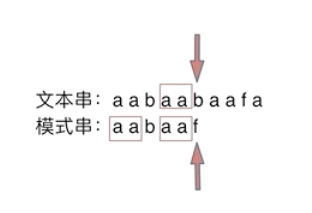
因为不匹配时,前面的子串aabaa,后缀 aa 和前缀 aa 相等,aa 既是前缀又是后缀,下次匹配时前缀aa一定相等,就不用匹配了,直接从aa的下一位字符b开始匹配就OK了。这里就用到了前五位子串aabaa的最长相等前后缀的长度为2。
所以如果有前缀表,匹配失败时就可以跳到已经匹配过的地方,不用再从头匹配了。
# 如何计算前缀表
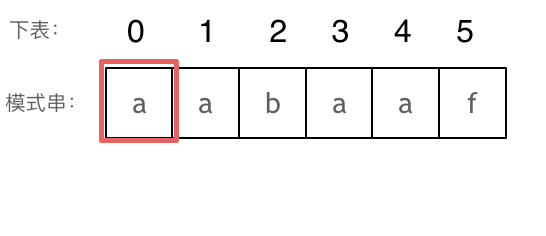
⬆️长度为前1个字符的子串a,最长相同前后缀的长度为0。(注意字符串的前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串;后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串。)
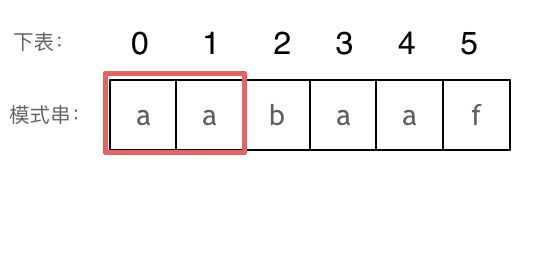
⬆️长度为前2个字符的子串aa,最长相同前后缀的长度为1。
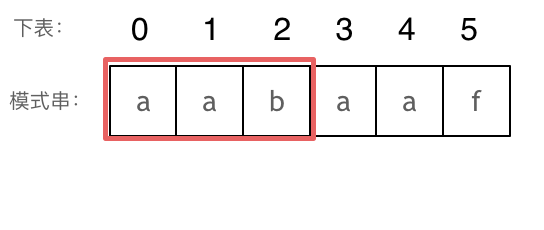
⬆️长度为前3个字符的子串aab,最长相同前后缀的长度为0。
以此类推:
- 长度为前4个字符的子串
aaba,最长相同前后缀的长度为1; - 长度为前5个字符的子串
aabaa,最长相同前后缀的长度为2; - 长度为前6个字符的子串
aabaaf,最长相同前后缀的长度为0。
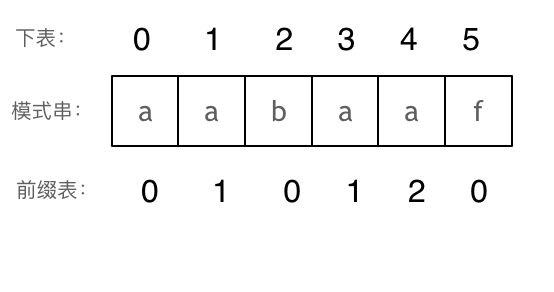
那么把求得的最长相同前后缀的长度组成一个数组,就是对应的前缀表。
可以看出模式串与前缀表对应位置的数字表示的就是:下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。
# 使用前缀表来匹配
再来看一下如何利用前缀表,在找到不匹配的字符时,指针应该移动到的位置。如动画所示:
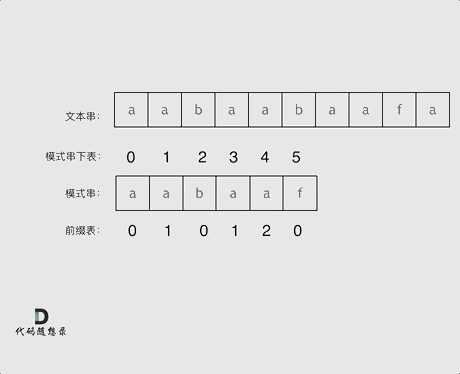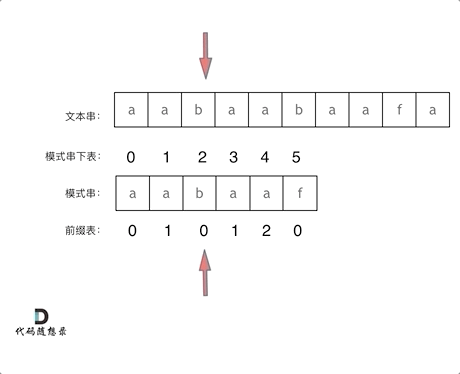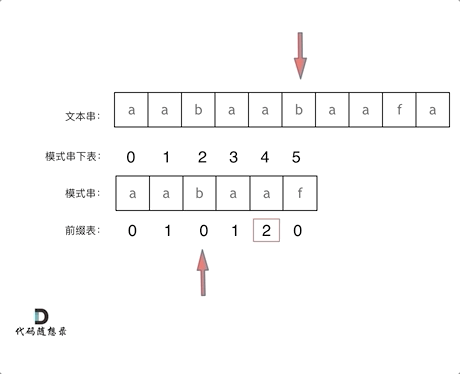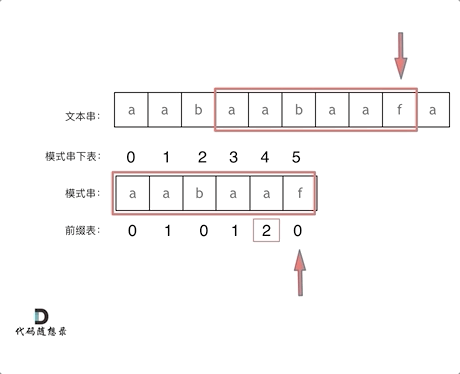
找到不匹配的位置,需要看它的前一个字符的前缀表数值是多少(因为要找前面字符串的最长相等前后缀的长度)。前一个字符的前缀表数值是2,所以把下标移动到2的位置继续匹配。
# 前缀表与next数组
next 数组可以是前缀表,也可以是对前缀表做过处理的数组。
有的人会把前缀表整体右移,首位赋值为-1。因为之前直接使用前缀表的话,需要找模式串匹配失败位置的前一位,整体右移之后可以直接找当前位置,比较方便。
还有一种是先把前缀表都-1,之后再+1,这个思路我还没有理解。
# 时间复杂度分析
m为模式串长度,n为文本串长度。
暴力解法显然是 O(n × m)
KMP:根据前缀表不断调整匹配的位置,可以看出匹配的过程是O(n)。计算生成next数组,时间复杂度是O(m)。所以整个KMP算法的时间复杂度是**O(n+m)**。
# 构造next数组
构造 next 数组其实就是计算模式串s的前缀表的过程,主要有3步:
- 初始化
- 处理前后缀不相同的情况
- 处理前后缀相同的情况
下面先写了从逻辑上易于理解的思路,先处理相同再处理不同。实际上应当是先处理前后缀不相同的情况,再处理前后缀相同的情况
初始化
定义两个指针 i 和 j 。j 指向前缀末尾位置,i 指向后缀末尾位置
// params:
// next 前缀表数组
// s 模式串
j := 0
next[0] = j
for i := 1; i < len(s); i++ {
// ...
}
处理前后缀相同的情况
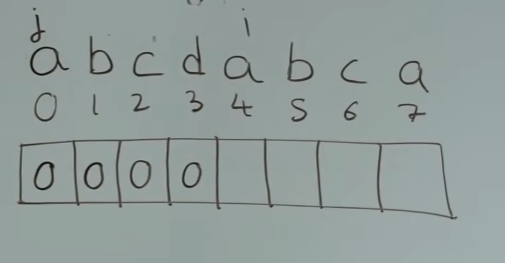
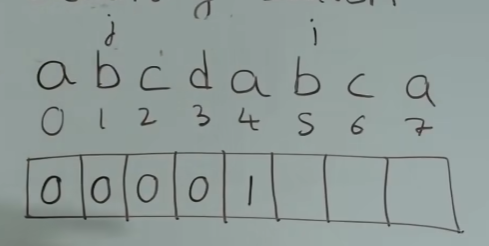
此时 s[j] == s[i] -> next[i] = next[j] + 1,i和j同时右移。
if s[j] == s[i] {
j++
}
next[i] = j此时这个求出来的1有什么意义呢?看下面的图:
现在匹配到x和b不相等了,要找它的前一位的前缀表的值,即a对应的值是1,这代表着已经有前缀和后缀a相同的情况,所以已经匹配了a,下一个点需要检查x和b。
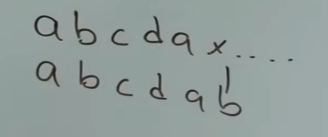



⬆️当下一个 s[j] == s[i] 时, s[i] = s[j] + 1,i和j同时右移,所以b对应的是2,c对应的是3。当比较到 d 和 a 时,就是前后缀不相同的情况了。
处理前后缀不相同的情况
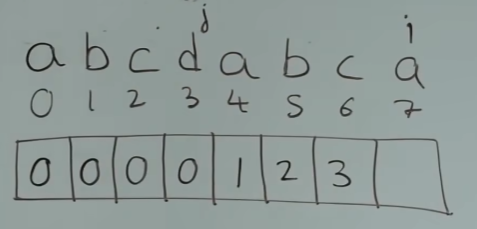
s[j] != s[i],此时j需要移动到前一个字符对应的值(即c对应的值),所以j移动到0,开始比较 s[j] 和 s [i],发现相等,所以 next[i] = next[j] + 1
为什么要移动到前一个字符?
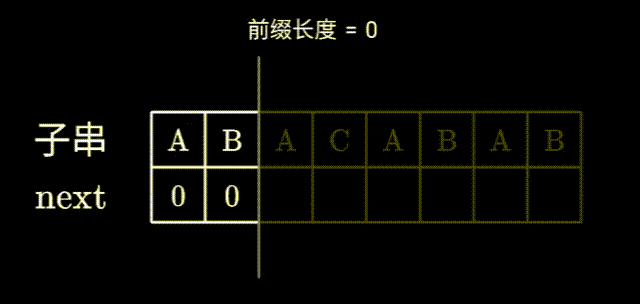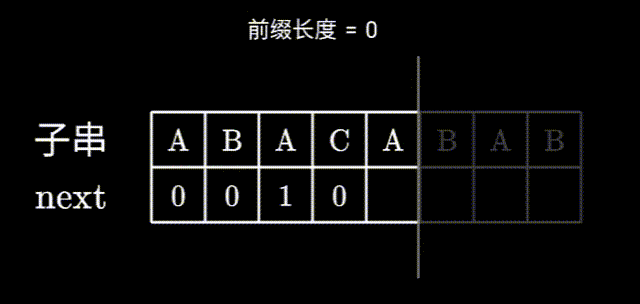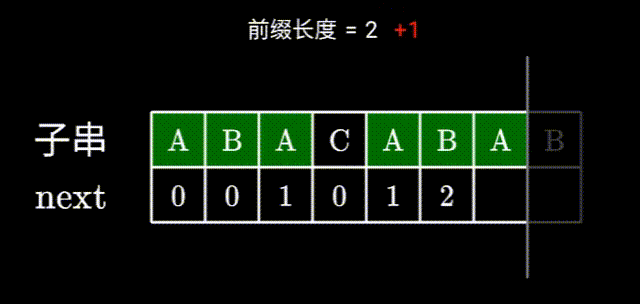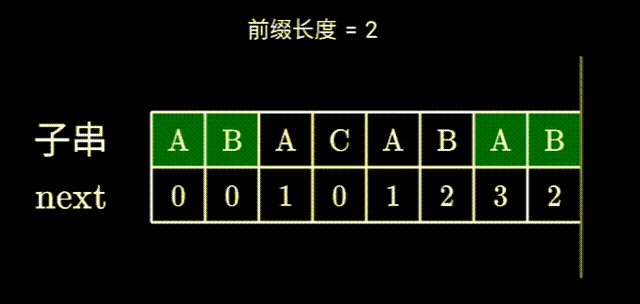
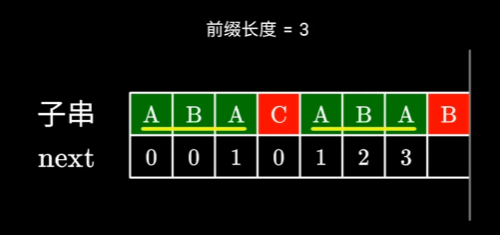
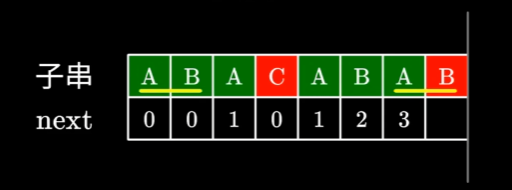
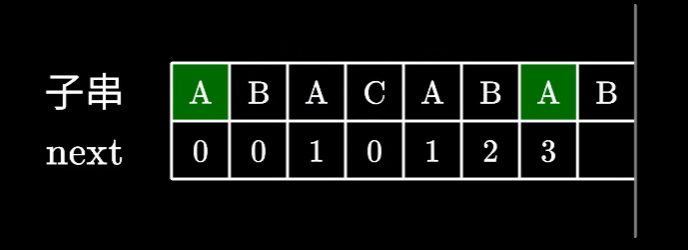
在
ABACABA中ABA已经构成了最长相等前后缀。此时
ABA已经无法与下一个字符构成更长的相等前后缀,那么我们就寻找一下是否存在更短的,比如 A 是可能与下个字符构成相等前后缀的。此时就要判断开头的A和红B前的A是否是相等前后缀。这一步不用暴力求解
其实不用暴力求解,因为我们得知左右两边的
ABA是相等的,要判断上图两个A是否相同,相当于直接在左边的ABA找相等前后缀,而左边的前后缀之前已经计算过了,也就是看 j 的前一位的前缀表的值。之后就是检查下一位字符是否相同,如果相同则可以构成一个更长的相等前后缀,长度+1即可。
求前缀表全过程的GIF:
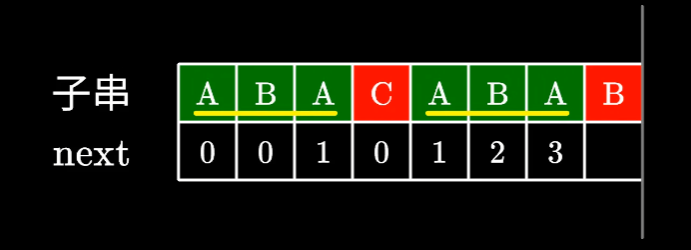
这里如果没明白为什么要移动到前一个字符,可以从06:11看这个视频:🔗【最浅显易懂的 KMP 算法讲解】
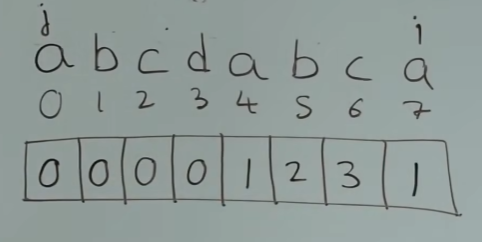
for j > 0 && s[j] != s[i] {
j = next[j-1]
}
if s[j] == s[i] {
j++
}
next[i] = j所以经过优化,实际上应当是先处理前后缀不相同的情况,再处理前后缀相同的情况。
// 前缀表无减一或者右移
// getNext 构造前缀表next
// params:
// next 前缀表数组
// s 模式串
func getNext(next []int, s string) {
j := 0
next[0] = j
for i := 1; i < len(s); i++ {
for j > 0 && s[i] != s[j] {
j = next[j-1]
}
if s[i] == s[j] {
j++
}
next[i] = j
}
}# 使用next数组来做匹配
func strStr(haystack string, needle string) int {
n := len(needle)
if n == 0 {
return 0
}
j := 0
next := make([]int, n)
getNext(next, needle)
for i := 0; i < len(haystack); i++ {
for j > 0 && haystack[i] != needle[j] {
j = next[j-1] // 回退到j的前一位
}
if haystack[i] == needle[j] {
j++
}
if j == n {
return i - n + 1
}
}
return -1
}# 完整代码
func strStr(haystack string, needle string) int {
n := len(needle) // 模式串的长度
if n == 0 {
return 0
}
j := 0 // 模式串中的指针
next := make([]int, n)
getNext(next, needle)
for i := 0; i < len(haystack); i++ {
if j > 0 && haystack[i] != needle[j] {
j = next[j - 1]
}
if haystack[i] == needle[j] {
j++
}
if j == n {
return i - j + 1 // 返回第一个匹配的下标所以+1
}
}
// 遍历完 haystack 都没有和 needle 完全匹配(j != n),说明 needle 不是 haystack 的一部分
return -1
}
func getNext(next []int, s string) {
j := 0
next[0] = j
for i := 1; i < len(s); i++ {
for j > 0 && s[j] != s[i] { // 前后缀不相等的情况
j = next[j-1]
}
if s[j] == s[i] {
j++
}
next[i] = j
}
}